Summary
We cannot determine a file’s “implementation language” with perfect certainty—especially for native binaries—but we can build a pragmatic classifier that performs well in real containers. We combine (in order) shebang parsing for scripts, magic-byte/container checks for known formats (ZIP/JAR, Java class files, PE/.NET), and non-executing inspection of ELF/PE metadata plus a small set of distinctive fingerprints (sections/notes, symbol mangling prefixes, and embedded build-info strings). The key is to prioritise deterministic signals first, treat native “C” as a fallback bucket, and keep safe defaults (notably: we avoid ldd unless we trust the binary).
Intro
Binaries do not include an explicit “written in X” label. However, toolchains leave fingerprints—sometimes obvious (a shebang), sometimes subtle (a section name or a mangled symbol). With a careful priority order and modest expectations, we can convert a file list into a useful language breakdown efficiently.
Detection strategy and priority order
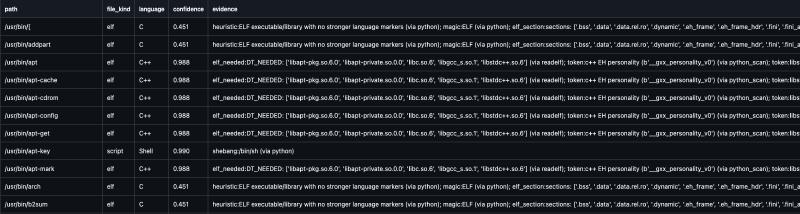
Our pipeline is layered: we apply the most authoritative, least ambiguous checks first, then fall back to heuristics only when necessary.
| |
We rely on shebang behaviour defined by Linux execve for interpreter scripts, making it reliable and inexpensive. For binaries, we first determine the container type (ELF/PE/ZIP/class file) using magic bytes. Once identified as ELF, we inspect metadata using non-executing tools (readelf, nm, strings) and scan for stable tokens.
Fingerprints per language
We use the following actionable fingerprints as evidence (not proof):
| Category | High-signal fingerprints |
|---|---|
| Python | Shebang includes python / python3 |
| Perl | Shebang includes perl |
| Shell | Shebang includes sh/bash/dash/zsh |
| JavaScript (Node) | Shebang #!/usr/bin/env node |
| Java | .class magic 0xCAFEBABE; JAR = ZIP with META-INF/ or .class |
| .NET / Mono | PE with CLR header; metadata signature 0x424A5342 |
| Go | ELF section .go.buildinfo; magic \xff Go buildinf: |
| Rust | Symbols with _R; rust_eh_personality |
| C++ | _Z mangling; __gxx_personality_v0; libstdc++ |
| C | Fallback if no stronger evidence |
| Other | Unknown or unsupported |
Reproducing the detection steps
We can replicate the classification process with the following commands:
| |
| |
| |
| |
Limitations and safe defaults
We avoid ldd by default because it may execute code on untrusted binaries. We prefer readelf -d or objdump -p for dependency inspection. Stripped or statically linked binaries reduce observable signals, often resulting in classification as “C (fallback)” or “Other”. Mixed-language binaries introduce ambiguity; our goal is a reproducible best-effort classification rather than certainty.
Call to action
We can implement a Python 3.11+ CLI that wraps this pipeline: read a file list (or scan a directory), classify each path, and output results (JSON + CSV) along with summary counts. The implementation should rely on non-executing tools (file, readelf, nm, strings) and Python-based parsing for shebang and magic bytes.
Example usage:
| |
This approach is sufficient for container audits, system analysis, and guiding deeper reverse-engineering efforts.
| |